Inicio
Para iniciar este proyecto, como es costumbre me di a la tarea de buscar proyectos en Github para poder basarme en ellos. Ya que empezar un proyecto tan ambicioso desde cero es algo muy complicado e innecesario. Entre todos los proyectos que logré encontrar dos fueron los que más me llamaron la atención.
Primer proyecto : deep-improvisation
Este proyecto está bastante interesante. La idea es agarrar un archivo MIDI, extraer sus características principales y plasmarlas en texto. Cuando se abre un archivo MIDI tiene la siguiente estructura:
midi.NoteOffEvent(tick=48, channel=0, data=[79, 64])
midi.NoteOnEvent(tick=10, channel=0, data=[79, 10])
midi.NoteOffEvent(tick=13, channel=0, data=[79, 64])
midi.NoteOnEvent(tick=62, channel=0, data=[76, 51])
midi.NoteOnEvent(tick=35, channel=0, data=[79, 52])
midi.NoteOffEvent(tick=13, channel=0, data=[76, 64])
midi.NoteOnEvent(tick=22, channel=0, data=[74, 23])
midi.NoteOnEvent(tick=1, channel=0, data=[62, 28])
Aquí lo que nos interesa es la secuencia que se crea de NoteOffEvent con los NoteOnEventy evidentemente
sus valores tick y data. Se puede notar que channelsiempre es 0 así que obviaremos ese dato.
Ahora, convertiremos esta secuencia en algo más sencillo para nuestra red, la cual tendrá la siguiente forma:
0_no_77_57
1_no_69_24
1_no_62_25
0_no_65_28
4_nf_74_64
13_nf_79_64
Aquí se puede notar que el primer valor representa el tick. no hace referencia a NoteOnEvent y
evidentemente nf hace referencia a NoteOffEvent. Y los 2 valores posteriores igual representan los
valores que se ilustran en data.
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(unique_chunks))))
model.add(Dense(len(unique_chunks))) # Número de caracteres únicos en nuestra cadena.
model.add(Activation('softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
model.fit(X, y,
batch_size=24,
epochs=25
)
Ahora, a partir de ese texto se aplica la red recurrente, en nuestro caso utilizamos un modelo que utiliza una LSTM de 128 nodos (células) en la primera capa. Luego tenemos una capa densa con nodos iguales a la cantidad única de caracteres en nuestras notas. Y finalmente una activación con softmax con RMSProp como optimizador.
Se utilizó un batch_size de 24 y 25 epochs.
Lo anterior son los únicos cambios considerables que se le aplicaron al proyecto anterior y se obtuvo el siguiente resultado.
Segundo proyecto.
El segundo proyecto y el que más interesante me pareció fue el de classical-piano-composer.
En este proyecto igual se trabaja utilizando archivos MIDI pero ahora se utiliza un archivo llamado
notas donde vienen las notas que se manejan en los archivos MIDI. Simplemente se hace un mapeo
de los archivos MIDI a una matriz donde cada nota se representa con un entero que va
de 0 a 1.
Una vez obtenida la matriz se aplica el siguiente modelo:
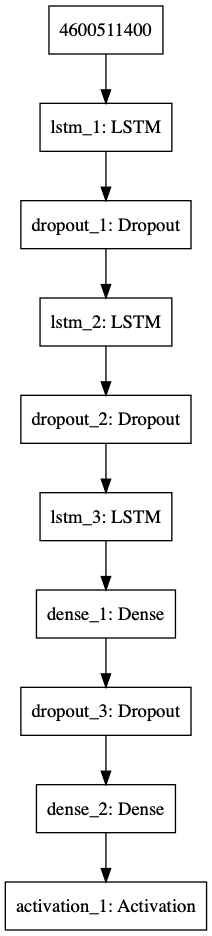
def get_model(network_input, n_vocab, weights=None):
""" create the structure of the neural network """
model = Sequential()
model.add(LSTM(
128,
input_shape=(network_input.shape[1], network_input.shape[2]),
))
model.add(Dropout(0.3))
model.add(LSTM(64, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(128))
model.add(Dense(64))
model.add(Dropout(0.3))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
if weights:
model.load_weights(weights)
return model
En comparación al proyecto original el número de células fue reducido en cada capa.
Se le añade una opción weights para permitir al modelo cargar pesos a la hora de compilarlo.
Se utilizó un batch_size de 16 y 25 epochs.
Estos fueron los cambios que se hicieron a la hora de entrenar el modelo.
Para generar el modelo, se le añadió una nueva característica y esta es la siguiente:
# generate 500 notes
for note_index in range(500):
prediction_input = numpy.reshape(pattern, (1, len(pattern), 1))
prediction_input = prediction_input / float(n_vocab)
prediction = model.predict(prediction_input, verbose=0)
_max = sum(prediction[0]) # Hacemos una suma de todas las predicciones
selection_prbs = [val/_max for val in prediction[0]] # Sacamos un arreglo de probabilidad de ser seleccionado.
index = numpy.random.choice(len(prediction[0]), p=selection_prbs) # Agarramos una nota basándonos en su fitness.
result = int_to_note[index]
prediction_output.append(result)
pattern.append(index)
pattern = pattern[1:len(pattern)]
return prediction_output
En vez de elegir la mejor nota siempre, se le añade una ruleta basada en qué tan probable es la nota. Para añadirle un poco de aleatoriedad y que pueda arrojar resultados diferentes cada vez.
Con estos cambios se realizaron 3 tests, cada uno con un optimizador diferente.
A continuación se muestran los diferentes resultados optenidos:
- sgd:
- Adam:
- RMSprop
El código de este último proyecto se encuentra disponible aquí
Modelo empleado
Conclusión
En cuanto al output, referenciando a los archivos de música me parece que el Adam y el RMSprop son los
que mejores resultaron arrojaron. Incluso me pareció curioso que el Adam empezó con notas más bajas
mientras que el RMSprop lo hizo con notas más altas. Siento que el resultado es descente considerando
los pocos epochs que se utilizaron y el tamaño de la red.
El primer proyecto en mi opinión es más intuitivo que el segundo, ya que maneja más claramente los archivos pero ambos son bastante claros y fáciles de implementar. Me gustó los resultados que dio cuando le añadí la característica de que en vez de que agarrara la mejor nota siempre, que lo hiciera basándose en las probabilidades. De esa manera le da un toque un poco más humano a la red en mi opinión.
Me queda claro la utilidad que tienen las redes recurrentes y sin duda veo lo fácil que son de implementarse. Ya sea desde utilizando texto hasta utilizando sonido directamente.